생물기기분석학 수업노트-5: 세포구성물질-4 (핵산)
- 차 례 -
1. 핵산의 구조
2. DNA 염기서열 결정-1: Sanger method
3. DNA 염기서열 결정-2: Maxam-Gilbert method
4. Human genome project
- 강 의 내 용 -
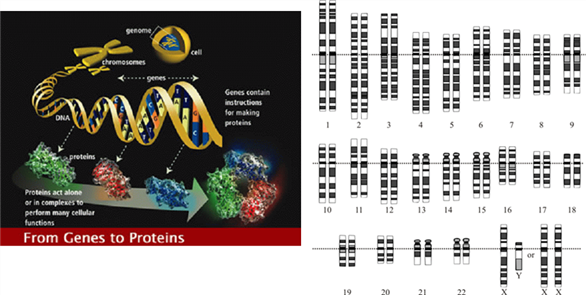
1. 핵산 (nucleic aid, DNA & RNA)
(1) DNA와 RNA
|
차이점 |
DNA |
RNA |
|
사용되는 당 (sugar) |
deoxyribose |
ribose (DNA와 다른 효소가 작용) |
|
사용되는 염기 (base) |
A,C,G + thymine (T) |
A,C,G + uracil (U: T와 마찬가지로 A와 상보적인 염기) |
|
사슬의 구성 |
double strand helix |
single strand (예외: 몇 viruses)→ 복잡한 2차 3차 구조 형성 |
|
분자량 |
매우 크다 |
거대분자이나 DNA의 수천 ~ 수백만분의 1 |
|
안정성 |
상대적으로 안정 |
대개 불안정 (single strand이므로) |
|
역할/종류 |
한가지 (genetic function) |
mRNA (genetic) tRNA, rRNA, ribozyme (functional) |
|
합성 효소 |
DNA polymerase |
RNA polymerase |
|
합성재료 |
dATP, dGTP, dCTP, dTTP |
ATP, GTP, CTP, UTP |
(2) RNA의 두 가지 역할: genetic and functional
1) 유전 작용: 유전 정보의 전달 (mRNA)
2) 기능 작용
a. 기능과 구조 (rRNA);
b. 전달 (tRNA)
c. 촉매 작용 (RNA enzymes)
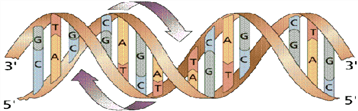
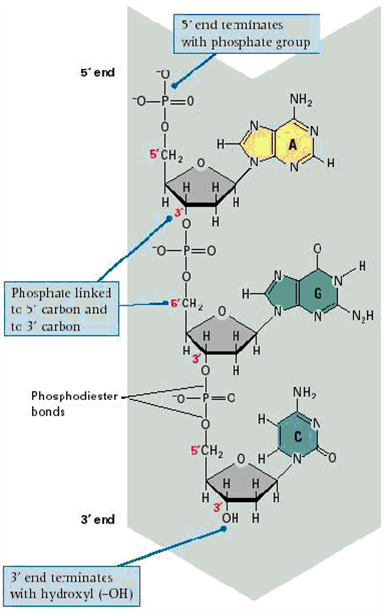
(3) DNA의 일차구조
1) 염기순서 (base sequence): -A-C-T
2) 방향성: 5‘→3’
2. DNA 염기서열 결정-1: Sanger method
http://highered.mcgraw-hill.com/sites/0072556781/student_view0/chapter15/animation_quiz_1.html
(Sanger Method)
http://www.biostudio.com/a_sitemap.htm - DNA sequencing
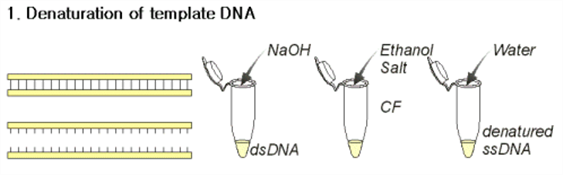
(1) 열처리 또는 NaOH를 써서 변성시킨 후 ethanol 로 급격히 침전시킴.
(2) denature 상태의 ssDNA (single stranded DNA)를 얻을 수 있음.
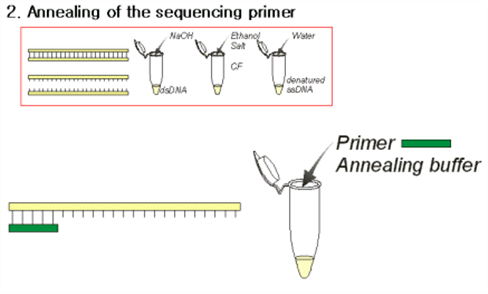
- sequencing primer (DNA)를 넣어 annealing 시킴.
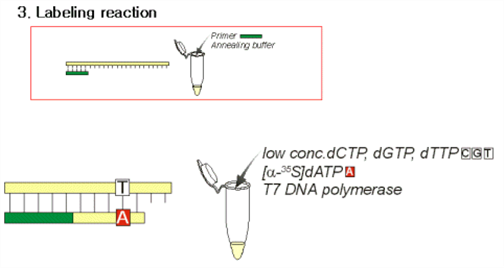
(1) 동위원소와 나머지 dNTP 를 넣고 효소를 넣어주면 새로운 DNA 가닥이 합성됨.
(2) 이 과정은 새로 합성되는 모든 DNA strand 를 동위원소로 표지하기 위한 과정.
(3) 너무 길게 합성이 되지 않기 위하여 dNTP를 낮은 농도로 넣어 줌.
(4) 반응속도를 쉽게 조절하기 위하여 반응도 상온에서 시행함.
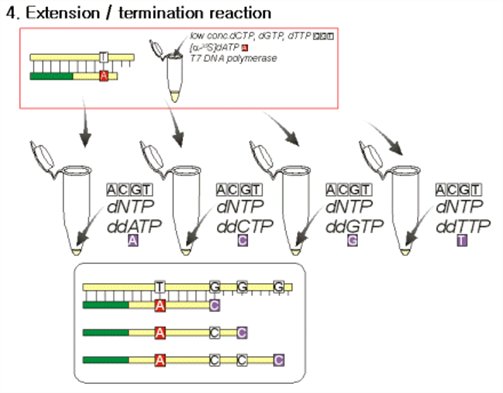
(1) DNA strand 가 합성되려면 반드시 3'-OH 가 노출되어 있어야 함.
(2) ddNTP 가 들어간 부분은 3'-H 로 되어 있게 되므로 더 이상 합성이 안 일어남.
(3) dNTP 가 들어가느냐 ddNTP 가 들어가느냐에 따라서 합성이 계속되거나 중지됨.
(4) 위 그림에서처럼 G 로 끝나는 자리에서 ddCTP가 들어가 반응 중지된 모든
strand를 얻을 수 있음.
(1) ddATP, ddCTP, ddGTP, ddTTP 가 들어있는 네 tube 에서 각각의 반응을 진행
(2) 각 tube 에는 특정한 염기서열로 끝나는 모든 종류의 DNA strand 가 존재하게 됨
(3) 위 그림에서 ddATP 를 넣은 tube 에서 반응시키면 tube 속에는 모두 ddATP 로 끝난 반응물이 생기게 되며,
(4) 이 때 그 길이에 해당하는 원래 DNA (template)의 염기 서열은 T 임을 알 수 있음.
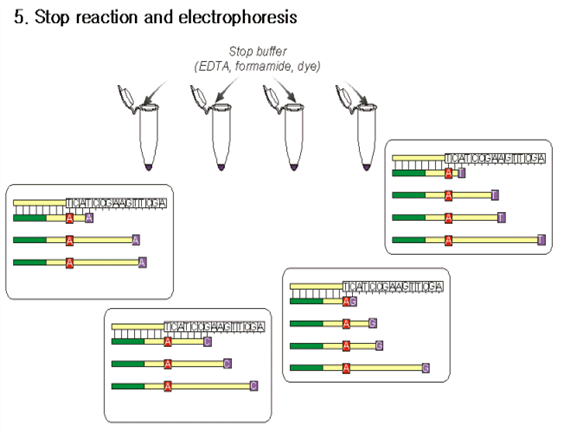
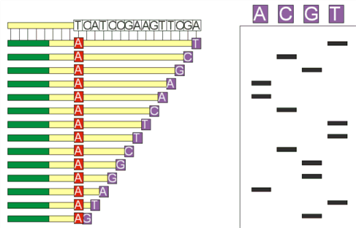
6. 반응물의 전기영동
(1) 위에서 얻은 4개의 반응물을 전기영동 함 (7 M urea 가 포함된 8% acrylamide gel)
(3) 이 gel은 두께가 매우 얇고 acrylamide의 특성상 하나의 염기 차이가 있어도
이동거리가 달라져 크기를 구별할 수 있음.
(4) 앞에서 반응시킨 네 개의 tube 를 각각 전기영동시켜 아래와 같은 결과를 얻음
(5) 각각의 전기영동 결과를 종합하여 염기 서열을 읽을 수가 있게 됨.
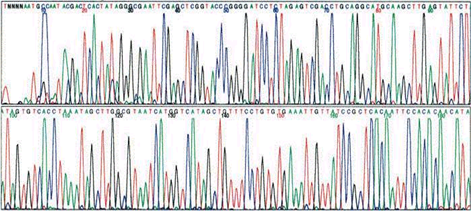
7. 자동분석기 (using fluorescent tags)
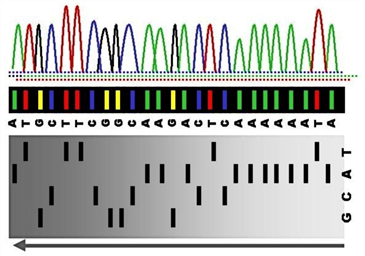
8. 참고; SDS-PAGE와 자동분석기의 비교
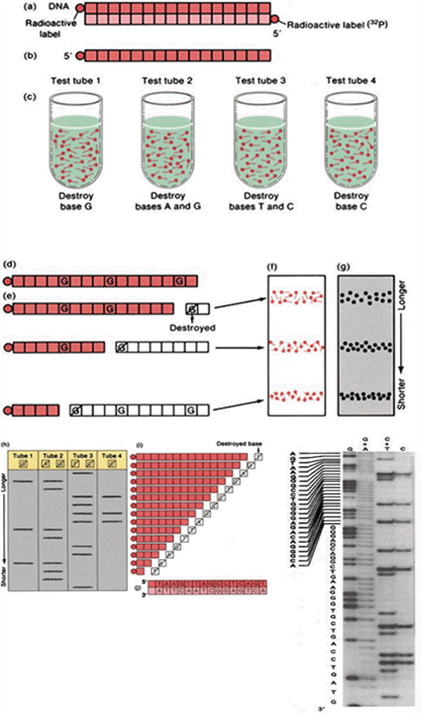
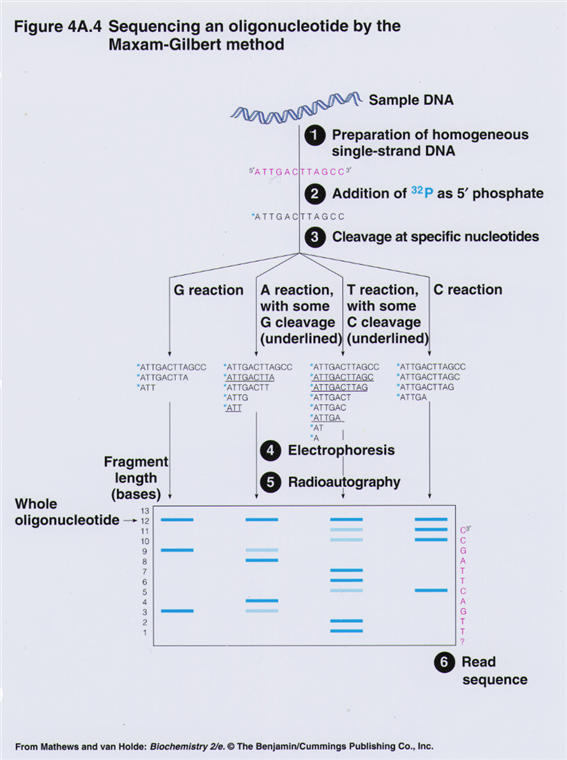
3. DNA 염기서열 결정-2: Maxam-Gilbert method
(1) 이중나선 DNA의 양 끝에 방사선 동위원소로 표시
(2) 이중나선 DNA를 단일 DNA로 denaturation시킨 후에 4개의 튜브에 나누어 반응
(3) 각 튜브에 특정 염기만을 절단하는 시약을 사용하여 ssDNA를 무작위적으로 절단
(4) 절단된 각 ssDNA 반응물을 전기영동하여 염기서열을 추정
4. Human genome project
(1) Human genome project
1) 사람 몸 안에 있는 모든 유전자를 해독한다는 이른바 인간게놈 계획
2) 미국을 중심으로 세계 각국에서 연구가 진행되어 지난 2003년에 종료
3) 사람 몸에는 3~4만개의 유전자가 약 30억 염기쌍의 염색체 DNA에 기록
4) 이용 부문
① 유전병이나 암 등의 질병의 진단·치료
② 뇌·신경계나 면역기구 등의 고차원적인 기능의 해명
③ 인류의 진화과정의 해석 등에 없어서는 안 될 정보
5) 연구 착수 16년 만에 인간의 23개 염색체를 전부 해독하는데 성공
6) 알려진 거대 DNA 염기서열의 비교
|
Comparative Sequence Sizes |
(Bases) |
|
(yeast chromosome 3) |
350 Thousand |
|
Escherichia coli (bacterium) genome |
4.6 Million |
|
Largest yeast chromosome now mapped |
5.8 Million |
|
Entire yeast genome |
15 Million |
|
Smallest human chromosome (Y) |
50 Million |
|
Largest human chromosome (1) |
250 Million |
|
Entire human genome |
3 Billion |
(2) What Does the Draft Human Genome Sequence Tell Us?
1) The human genome contains 3164.7 million chemical nucleotide bases (A, C, T, and G).
2) The average gene consists of 3000 bases, but sizes vary greatly, with the largest known human gene being dystrophin at 2.4 million bases.
3) The total number of genes is estimated at 30,000 —much lower than previous estimates of 80,000 to 140,000.
4) Almost all (99.9%) nucleotide bases are exactly the same in all people.
5) The functions are unknown for over 50% of discovered genes.
6) Less than 2% of the genome codes for proteins.
7) Repeated sequences that do not code for proteins ("junk DNA") make up at least 50% of the human genome.
8) Repetitive sequences are thought to have no direct functions, but they shed light on chromosome structure and dynamics.
9) Over time, these repeats reshape the genome by rearranging it, creating entirely new genes, and modifying and reshuffling existing genes.
9) During the past 50 million years, a dramatic decrease seems to have occurred in the rate of accumulation of repeats in the human genome.