| 글로벌비즈니스학과 황욱연 교수 |
| 프로필 | R Shiny Demo | 연구실적 | 컨설팅 | 갤러리 |
|
|
|
1. The collaborative filtering approaches for the binary market basket data with the high dimensional cold-start problems 1.1. Mild, A. and Reutterer, T. (2003), An improved collaborative filtering approach for predicting cross-category purchase based on binary market basket data, Journal of Retailing and Consumer Services, 10(3), 123–133. 1.2. Wook-Yeon Hwang (2025), New Conditional Probability-based Collaborative Filtering for the Binary Market Basket Data with the High Dimensional Cold-Start Problem, Information Sciences, Volume 689, 121475.
2. The experimental design
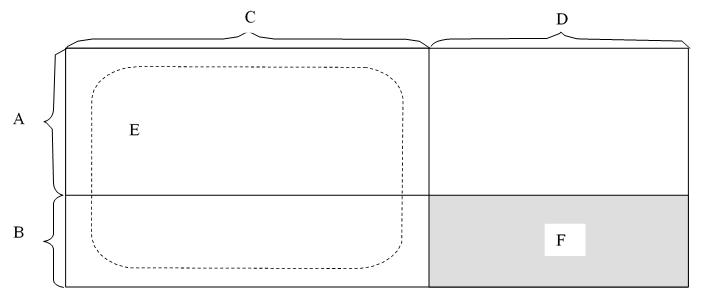
A : Training users Figure. Division of the experimental data set for the CF approach.
3. R Shiny GUI instruction - Upload a csv file comprising zeros and ones - Only the first 20 users are selected as training users(A), while the first 80% of the items is selected as training items(C). - The performance measure is based on the precision, which is generally used in information retrieval research and defined by
- The precision for Top-N (N=1,...,10) is calculated.
4. R Shiny GUI link: Click here
|
| 부산광역시 서구 구덕로 225(부민동 2가) 동아대학교 국제대학 글로벌비즈니스학과 연구실 B5-0363호 | TEL : 051-200-8711 Copyright @Donga-A University. All rights reserved. |